Guidelines for Deploying Cloud Governance Remediation Policies
Within many organizations, development and application teams are increasingly accessing cloud resources through native consoles and APIs. Given this evolution, it is becoming increasingly difficult to respond to potentially risky and costly misconfigurations in a timely or efficient manner — and these challenges only grow more significant as organizations continue to scale operations in the cloud. To establish effective cloud governance, teams must employ automated remediation and policy enforcement.
However, as many teams start deploying governance policies — especially those that include automated remediation — they begin to see that these changes cause potential disruptions and confusion for development teams. Below are some guidelines that will help you avoid these negative outcomes.
Document and Share Policies Ahead Of time
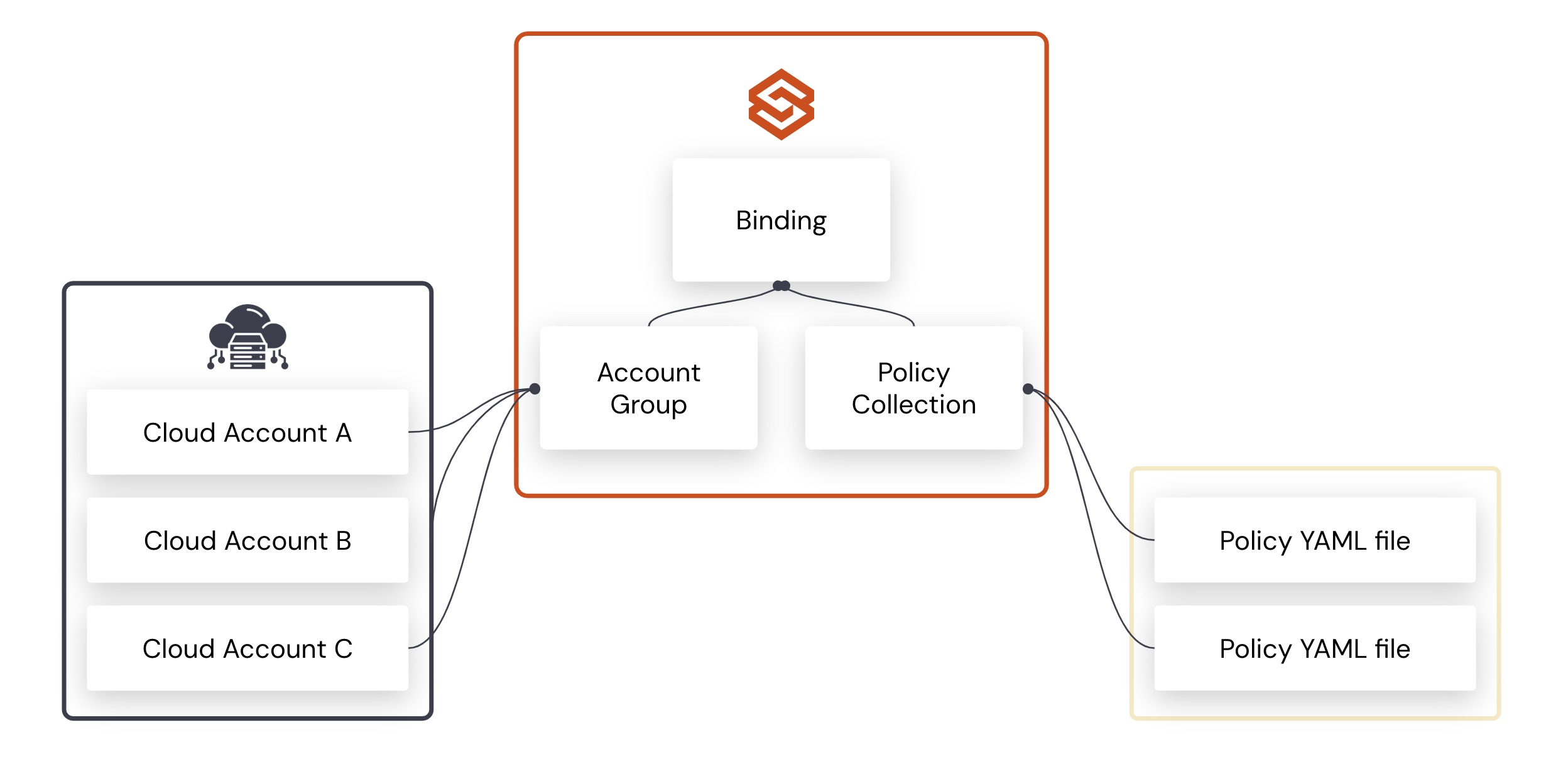
As a first step, your policies should be available in a central repository, along with appropriate commentary that describes the policies and deployment schedule. With governance as code tools like Cloud Custodian, teams can employ an easy-to-use, declarative language to manage and automate policy deployment. The language is abstract and high-level, making it easy for development, security, and FinOps teams to understand and collaborate on policies.
Your governance policies should be shared several weeks before deployment, so developers have plenty of time to plan for changes and add the work to their team’s backlog. Cloud governance or engineering teams need to make policies and deployment schedules broadly available to have high organizational visibility. These communications must include details about each policy scheduled for deployment, including where it will be deployed. In addition, it is also important to articulate why the policy is being implemented, such as how it helps the company optimize costs or meet industry compliance standards. Having the policies planned out in advance helps reduce potential friction and minimize the impact on associated teams.
Establish Regular Communications With Development Teams
It is important to have well-established communications and regularly scheduled calls with all affected users, including developers, project managers, divisional managers, FinOps teams, cloud groups, and security teams. These communications ensure everyone knows the upcoming policies and what to expect from the remediations. During these calls, you will want to review the policy deployment calendar to detail how the last policy deployment went and describe upcoming deployments. This allows teams to discuss any potential concerns or issues and identify which resources might need to be exempted from a policy.
Post-deployment, these calls can enforce continuous governance, review existing policies, and adjust due to changing business needs and maturity levels.
Do Dry Runs of Policy Implementations and Share Early Results
It is recommended to start remediation on new resources only. Net-new resources are easier to remediate as developers have not fully configured them, so there is less chance of losing the time invested. These remediations can be handled via event-mode policies triggered by resource creation events. These activities can also be handled via poll-mode policies if the resource has a creation date attribute that can be filtered on. In this way, you can enforce policies on all new resources going forward without impacting existing resources. This approach tends to lead to a smoother transition for developers.
If you plan to remediate existing resources, provide DevOps teams with impacted resource reports before deploying your policies. This will help ensure developers have adequate visibility and time to update their infrastructure as code templates and fix resource configurations. You can either generate reports of non-compliant resources or, if your cloud governance tool allows, automatically notify development teams of non-compliant resources. Typically this notification would give the affected user a list of resources that need to be fixed and information on what resource setting needs to be modified for the resource to comply with the upcoming policy deployment.
As an example, if you are using Cloud Custodian, you can do a dry run and generate reports on the policies implemented. This can be achieved either by running the upcoming policies with a “–dryrun” flag or by just removing all actions from the policies. After the policies have been executed, you can run a “custodian report” command to generate reports of resources affected. These reports can be delivered in multiple formats and distributed to affected users. If you are running the Stacklet platform, you can deploy the policies without actions, and then, from the policies details page, you can view the “Resources” tab and export the list of affected resources for distribution.
Performing this step will reduce the chances of developers having to contend with last-minute surprises and scrambling to resolve issues. Ultimately, this helps reduce the friction of policy remediations.
Phase in Policy Deployment
Many policies include actions or remediation, such as deleting instances that are publicly exposed or turning off development machines that are running on the weekend. We recommend deploying these policies in stages for different environments.
Policies should always be tested in a sandbox or test environment before deployment. When possible, it is a best practice to first deploy your new policies to canary cloud accounts, which helps to ensure mainstream development environments aren’t affected. Once policies have been deployed to canary accounts for around a week and no issues have arisen, the policies can safely be deployed to all development accounts. After running a week or two in development accounts without issue, the policies can then be deployed to all production accounts. By deploying policies in different stages, you can minimize risk. Through this approach, you can start with the lowest-risk accounts and slowly move policies up to the higher-risk production accounts while allowing sufficient testing time in each environment.
Once these policies are deployed in production, it might make sense to have notifications only enabled for an initial couple of weeks and then automatically enforced. This can also help teams avoid disruptions, learn about exceptions, and get advance notice of changes required. For example, an off-hour policy that identifies development instances running on a weekend can notify the resource owner and turn off the resource the following week if it’s still running.
Categories
- Automated Remediation
- Cloud Governance