Stop AI Waste, Prevent Costly Overruns: Cloud GPU Optimization with Stacklet
Cloud GPU optimization is crucial for businesses leveraging AI and Large Language Model (LLM) applications. Graphics Processing Units (GPUs) have become the backbone of modern AI workloads, enabling the execution of complex computations at an unprecedented scale. With the growing demand for AI-driven solutions, cloud providers have made GPU resources more accessible. Organizations can now deploy GPU-powered workloads with minimal upfront capital, reduced operational overhead, shorter lead times, and faster deployment times. This ease of access allows businesses to focus on innovation rather than infrastructure management, bypassing the traditionally challenging procurement and setup processes.
However, while cloud-based GPU access provides significant advantages, it presents new challenges. The flexibility of the cloud can lead to inefficiencies that drive up operational expenses, especially when AI applications or experiments are not carefully managed.
Challenges in Cloud-Based GPU Utilization
Despite the benefits, several challenges arise when organizations leverage cloud GPUs for AI workloads (similar to using compute resources in the cloud). These challenges often result in unnecessary costs and operational inefficiencies, including:
- Unused GPU Resources: Engineering teams may provision expensive GPU instances for experimentation but forget to decommission them after use, leading to wasted resources and soaring costs.
- Incorrect GPU Selection: Cloud providers like AWS and Azure offer numerous GPU options, from cost-effective to high-performance models. Choosing an inappropriate tier can significantly impact costs. For example, using an NVIDIA H100 instance when a less powerful, more affordable instance could suffice.
- Cost Awareness and Best Practices: Many teams lack the necessary financial expertise to analyze GPU utilization effectively. They may not have visibility into key cost-driving metrics, leading to suboptimal decision-making and inflated expenses.
- Inadequate Performance Insights: Organizations may overprovision resources without comprehensive insights into GPU workload performance. For instance, using a GPU with higher VRAM when you don’t need to can result in unnecessary spending.
- Delayed Actions and Automation Gaps: Timely actions are crucial to optimizing GPU usage. Choosing the wrong instance could cost you tens of thousands per month if not hundreds of thousands. The absence of timely and automated detection and enforcement mechanisms can result in prolonged inefficiency, further escalating costs.
Organizations need the ability to make informed decisions based on real-time insights into GPU performance, utilization, and cost. Effective usage governance and automation strategies are essential to ensure that GPU resources are right-sized, properly allocated, and efficiently utilized to maximize return on investment.
Stacklet Helps You Optimize Cloud-based GPUs and Avoid Expensive AI Missteps
Stacklet Platform, cloud governance as code solution, can help organizations continuously detect and automatically optimize GPU usage through deeper metric based actionable insights and remediation workflows. These workflows can take immediate action or trigger automated processes to ensure optimal performance and cost-efficiency.
Built on the Cloud Custodian open-source project, Stacklet provides out-of-the-box policies and a powerful policy engine to deliver immediate insights into cloud environments. This enables organizations to drive behavioral change within teams, ensuring that resources are used efficiently and cost-effectively. Stacklet’s comprehensive approach allows teams to proactively identify underutilized or misconfigured GPU instances, helping to avoid unnecessary costs while maintaining performance needs.
With the addition of recent capabilities, here are a few example areas where Stacklet can help optimize GPU usage in the cloud:
- Deeper Insights into Usage: Stacklet provides comprehensive metric support, offering visibility into your GPU infrastructure from traditional VM metrics to fine-grained GPU metrics, including GPU utilization and VRAM usage. This enables organizations to make data-driven decisions, optimize resource allocation, and maximize cost-efficiency.
Stacklet Policy Example: In AWS, find instances using less than 640GB VRAM and are running on p5e instances for a 10% savings. Automatically notify the owner of the resource owner, open a Jira ticket, and recommend switching to an instance type with less VRAM. Note: At $100k instance spend for training LLMs, this single policy can easily save $10,000 per month)
Stacklet Policy Example: In AWS, find EC2 Capacity Reservations configured using RHEL with HA and notify the user to recommend switching to generic Linux instead. In AWS, using the wrong operating system can also lead to unnecessary spending. Using RHEL HA, a separate charge roughly equivalent to 10% of the instance on-demand cost is added, versus a $0 charge for generic Linux.
With both policies, you can reduce your GPU spend by up to 20%.
- Automatic Identification of Unused Resources and Remediation Workflows: The Stacklet Platform helps identify underutilized GPUs based on custom criteria or predefined best-practice thresholds. Organizations can automatically pause GPU-attached instances that are under-utilized based on custom criteria – such as idle instances used in development environments – or trigger remediation workflows to safely de-provision unused instances with notifications and escalation.
Stacklet Policy Example: Identify running Microsoft Azure GPU-based Virtual Machines currently running at 1% GPU utilization or less. This policy uses industry-standard metrics aggregators for GPU utilization (telegraph-agent and Nvidia-semi metrics).
- Automatic Identification of Inaccurate GPU Class and Notifications: Stacklet can help identify instances where a less expensive GPU tier would suffice, enabling organizations to optimize spending by triggering alerts and recommendations for resizing.
Stacklet Policy Example: In Azure, the number of GPUs attached to an instance is configurable. For example, a policy can identify ML training workloads with low GPU utilization (e.g., under 30%), detect instances running with two H100 GPUs, and recommend downsizing to a single H100 GPU. This adjustment alone could result in significant savings of up to 50% by switching to a more appropriate instance type.
- Prevent Costly GPU Usage and Drive Behavioral Change: Stacklet helps organizations proactively manage GPU costs by warning or blocking incorrect provisioning attempts from build to runtime. With Stacklet, you can define or use out-of-the-box policies for GPU usage best practices or tagging and apply these rules against Infrastructure as Code (IaC) (e.g., Terraform). Below is a screenshot of a sample policy that blocks the provisioning of GPU instances by someone not part of the Applied AI team.
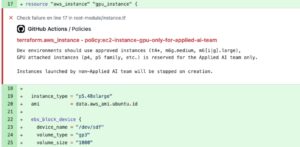
But let’s face it, very few organizations are 100% IaC compliant or 100% Terraform. Stacklet can also detect and enforce policies at runtime during provisioning, whether through IaC, ClickOps, or anything in between, triggering automated notifications or action workflows.
Stacklet Policy Example: A policy could terminate instances with GPUs created by resource owners outside of an approved exception list and notify them, guiding them to request access or provisioning rights.
Notifications at build and runtime (or any stage in between) can also be enriched with best practices and additional links to educate and drive cost awareness among data engineering or infrastructure teams.
- Frictionless Policy Deployment: Stacklet enables seamless, automated policy deployment without requiring engineers to make code changes. These policies are written in a simple, declarative format, making them easy for data, application, and infrastructure engineering teams to understand, manage, and update as needed.
- Cross-Account and Cloud GPU Usage Optimization Analysis: Stacklet provides out-of-the-box and customizable dashboards and a real-time asset inventory. This unified view lets you analyze GPU-centric instance usage across multiple accounts or clouds, making it easy to identify cross-cloud optimization opportunities and cost variances. You can easily compare pricing across providers and discover which provider is most cost-effective for you. This information is also useful for your savings and discount plan discussions with your team and cloud providers.
If you are looking to get a demo of Stacklet, please sign up here.
Categories
- Cloud Governance
- cost optimization
- FinOps